MALT: Improving Reasoning with Multi-Agent LLM Training
Abstract
Large Language Models (LLMs) often produce answers with a single chain-of-thought, which restricts their ability to explore reasoning paths or self-correct flawed outputs in complex tasks. In this paper, we introduce MALT (Multi-Agent LLM Training), a novel post-training strategy that divides the reasoning process into generation, verification, and refinement steps using a sequential pipeline of heterogeneous agents. During data generation, each agent is repeatedly sampled to form a multi-agent search tree, where final outputs are graded against ground-truth data. We then apply value iteration to propagate reward signals back to each role-conditioned model, automatically producing multi-agent post-training data without human or teacher-model supervision. Our off-policy approach allows each agent to specialize by learning from correct and incorrect trajectories, ultimately improving the end-to-end reasoning chain. On MATH, GSM8K, and CSQA, MALT surpasses the same baseline LLM with a relative improvement of 15.66%, 7.42%, and 9.40% respectively, making it an important advance towards multi-agent cooperative training.
System Architecture
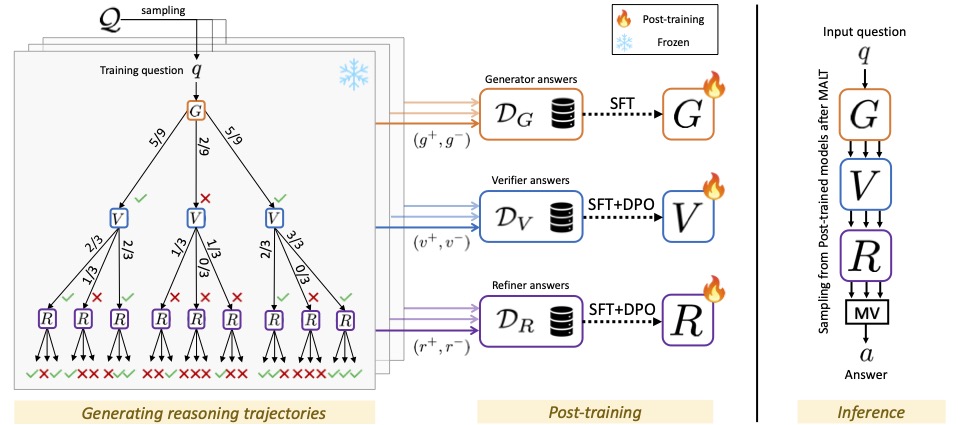
MALT Method Overview. Given an input, we consider a three-agent system composed of a Generator for initial answer production, a Verifier providing a critique, and a Refinement Model integrating all intermediate reasoning steps into a final output. For questions in the training set, we introduce a tree search and credit assignment process (Left) to generate synthetic datasets with reasoning trajectory preference pairs for each model. These are used to post-train individual models (Center). During inference over the test-set, we perform three parallel sequential passes through the multi-agent setup, and return the final answer obtained via majority voting (Right).
Performance Analysis
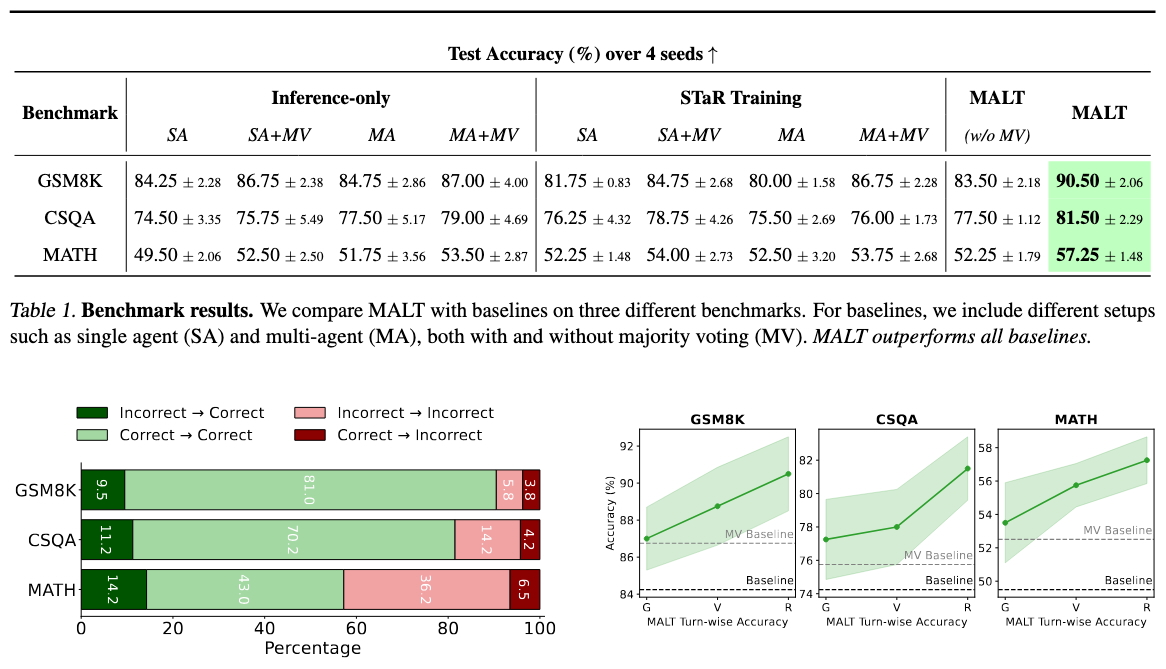
Analysis of MALT performance. Left: Transition patterns showing how MALT improves correct answers while reducing incorrect ones. Right: Turn-wise accuracy analysis showing how Generator (G), Verifier (V), and Refinement (R) agents contribute to overall performance. MALT significantly outperforms baselines across all benchmarks.
Results
MALT achieves an accuracy of 57.25%, 81.50%, and 90.50% on MATH, CSQA, and GSM8K. Overall, MALT significantly outperforms all baselines, including all settings with supervised fine-tuned models. Over the base model's performance as a generator, MALT achieves relative improvements of 15.66%, 9.40%, and 7.42% on MATH, CSQA, and GSM8K. This demonstrates the reasoning efficacy of our search and attribution based data generation, post-training, and inference pipeline in MALT across benchmarks of varying difficulty.
- MATH: 15.66% relative improvement
- GSM8K: 7.42% relative improvement
- CSQA: 9.40% relative improvement
These results highlight the effectiveness of the multi-agent training approach in enhancing reasoning capabilities of LLMs, particularly for complex problem-solving tasks.
BibTeX
@article{motwani2024malt,
title={MALT: Improving Reasoning with Multi-Agent LLM Training},
author={Motwani, Sumeet Ramesh and Smith, Chandler and Das, Rocktim Jyoti and Rafailov, Rafael and Laptev, Ivan and Torr, Philip H. S. and Pizzati, Fabio and Clark, Ronald and de Witt, Christian Schroeder},
journal={arXiv preprint arXiv:2412.01928},
year={2024}
}Correspondence
For inquiries, please contact Sumeet Ramesh Motwani (sumeet.motwani@eng.ox.ac.uk) or Christian Schroeder de Witt (cs@robots.ox.ac.uk).